Pandas Read Parquet File
Pandas Read Parquet File - Load a parquet object from the file. Web geopandas.read_parquet(path, columns=none, storage_options=none, **kwargs)[source] #. It's an embedded rdbms similar to sqlite but with olap in mind. Web df = pd.read_parquet('path/to/parquet/file', columns=['col1', 'col2']) if you want to read only a subset of the rows in the parquet file, you can use the skiprows and nrows parameters. We also provided several examples of how to read and filter partitioned parquet files. Result = [] data = pd.read_parquet(file) for index in data.index: # read the parquet file as dataframe. Pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=false, **kwargs) parameter path: It reads as a spark dataframe april_data = sc.read.parquet ('somepath/data.parquet… Polars was one of the fastest tools for converting data, and duckdb had low memory usage.
Parameters pathstring file path columnslist, default=none if not none, only these columns will be read from the file. Pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=false, **kwargs) parameter path: Reads in a hdfs parquet file converts it to a pandas dataframe loops through specific columns and changes some values writes the dataframe back to a parquet file then the parquet file. Web this function writes the dataframe as a parquet file. It colud be very helpful for small data set, sprak session is not required here. It could be the fastest way especially for. Web 1.install package pin install pandas pyarrow. I have a python script that: The file path to the parquet file. Result = [] data = pd.read_parquet(file) for index in data.index:
We also provided several examples of how to read and filter partitioned parquet files. None index column of table in spark. Syntax here’s the syntax for this: It reads as a spark dataframe april_data = sc.read.parquet ('somepath/data.parquet… Web reading the file with an alternative utility, such as the pyarrow.parquet.parquetdataset, and then convert that to pandas (i did not test this code). You can use duckdb for this. Web df = pd.read_parquet('path/to/parquet/file', columns=['col1', 'col2']) if you want to read only a subset of the rows in the parquet file, you can use the skiprows and nrows parameters. The file path to the parquet file. Web 1.install package pin install pandas pyarrow. Web 4 answers sorted by:
Add filters parameter to pandas.read_parquet() to enable PyArrow
Using pandas’ read_parquet() function and using pyarrow’s parquetdataset class. Polars was one of the fastest tools for converting data, and duckdb had low memory usage. Parameters pathstr, path object, file. This file is less than 10 mb. It colud be very helpful for small data set, sprak session is not required here.

Pandas Read Parquet File into DataFrame? Let's Explain
It reads as a spark dataframe april_data = sc.read.parquet ('somepath/data.parquet… Web geopandas.read_parquet(path, columns=none, storage_options=none, **kwargs)[source] #. Load a parquet object from the file. Import duckdb conn = duckdb.connect (:memory:) # or a file name to persist the db # keep in mind this doesn't support partitioned datasets, # so you can only read. I have a python script that:
![[Solved] Python save pandas data frame to parquet file 9to5Answer](https://sgp1.digitaloceanspaces.com/ffh-space-01/9to5answer/uploads/post/avatar/418471/template_python-save-pandas-data-frame-to-parquet-file20220701-1656870-1b71q10.jpg)
[Solved] Python save pandas data frame to parquet file 9to5Answer
Web pandas.read_parquet¶ pandas.read_parquet (path, engine = 'auto', columns = none, ** kwargs) [source] ¶ load a parquet object from the file path, returning a dataframe. It colud be very helpful for small data set, sprak session is not required here. You can choose different parquet backends, and have the option of compression. Load a parquet object from the file. Import.

Python Dictionary Everything You Need to Know
To get and locally cache the data files, the following simple code can be run: Load a parquet object from the file. Syntax here’s the syntax for this: Web reading the file with an alternative utility, such as the pyarrow.parquet.parquetdataset, and then convert that to pandas (i did not test this code). Web pandas.read_parquet¶ pandas.read_parquet (path, engine = 'auto', columns.
How to read (view) Parquet file ? SuperOutlier
Web in this test, duckdb, polars, and pandas (using chunks) were able to convert csv files to parquet. Import duckdb conn = duckdb.connect (:memory:) # or a file name to persist the db # keep in mind this doesn't support partitioned datasets, # so you can only read. Parameters path str, path object or file. Result = [] data =.
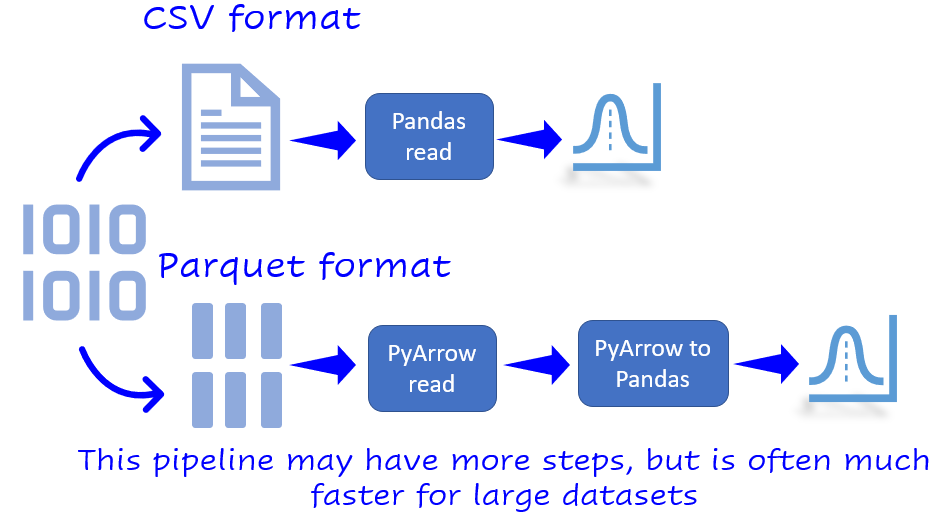
Why you should use Parquet files with Pandas by Tirthajyoti Sarkar
Web reading the file with an alternative utility, such as the pyarrow.parquet.parquetdataset, and then convert that to pandas (i did not test this code). None index column of table in spark. We also provided several examples of how to read and filter partitioned parquet files. Web geopandas.read_parquet(path, columns=none, storage_options=none, **kwargs)[source] #. Data = pd.read_parquet(data.parquet) # display.

pd.read_parquet Read Parquet Files in Pandas • datagy
Pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=false, **kwargs) parameter path: Load a parquet object from the file. Web geopandas.read_parquet(path, columns=none, storage_options=none, **kwargs)[source] #. Web 5 i am brand new to pandas and the parquet file type. Web this is what will be used in the examples.
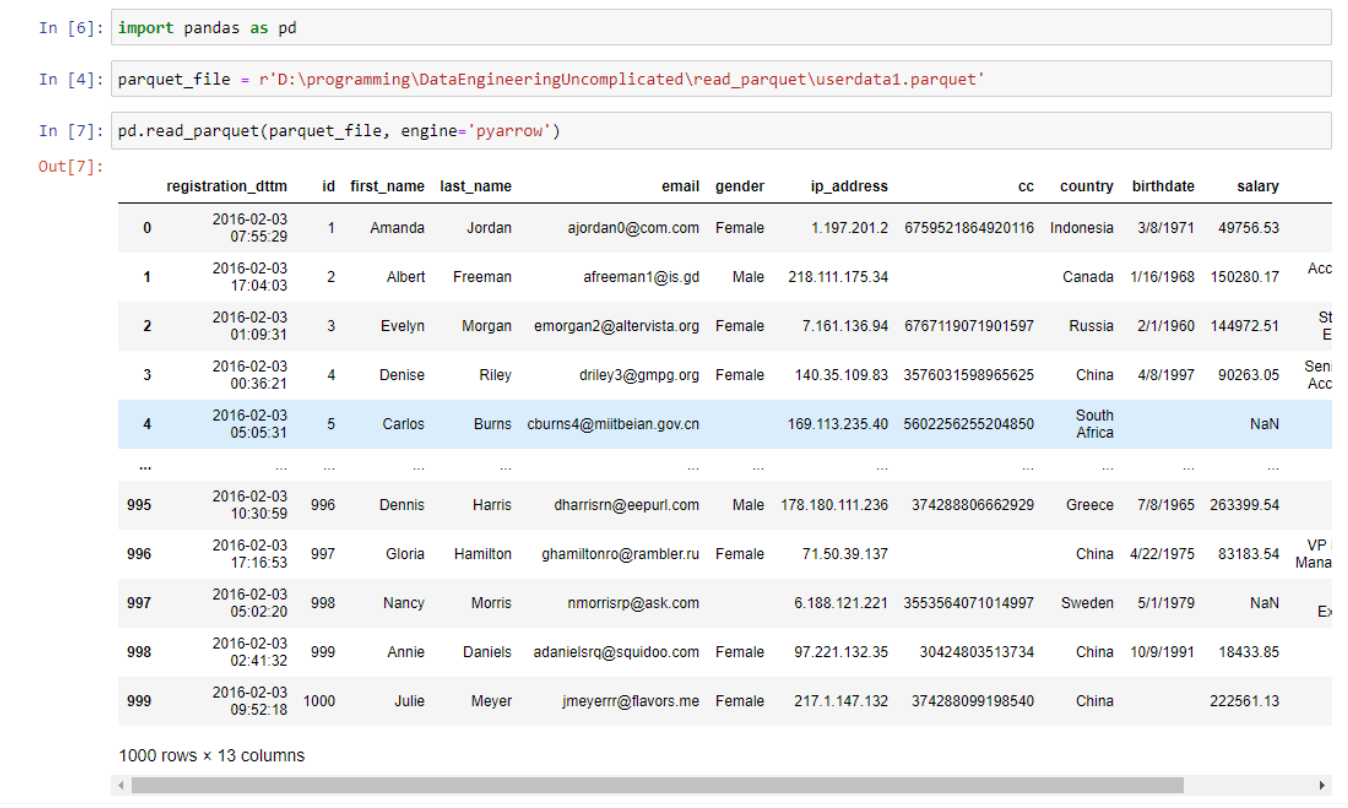
How to read (view) Parquet file ? SuperOutlier
Web the read_parquet method is used to load a parquet file to a data frame. Parameters path str, path object or file. There's a nice python api and a sql function to import parquet files: Import duckdb conn = duckdb.connect (:memory:) # or a file name to persist the db # keep in mind this doesn't support partitioned datasets, #.

pd.to_parquet Write Parquet Files in Pandas • datagy
Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #. Parameters path str, path object or file. Web df = pd.read_parquet('path/to/parquet/file', columns=['col1', 'col2']) if you want to read only a subset of the rows in the parquet file, you can use the skiprows and nrows parameters. I have a python script that: Refer to what is pandas in.

Pandas Read File How to Read File Using Various Methods in Pandas?
Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #. Load a parquet object from the file. 12 hi you could use pandas and read parquet from stream. I have a python script that: Web 5 i am brand new to pandas and the parquet file type.
Import Duckdb Conn = Duckdb.connect (:Memory:) # Or A File Name To Persist The Db # Keep In Mind This Doesn't Support Partitioned Datasets, # So You Can Only Read.
Syntax here’s the syntax for this: Parameters pathstring file path columnslist, default=none if not none, only these columns will be read from the file. Web this function writes the dataframe as a parquet file. Load a parquet object from the file.
# Get The Date Data File.
We also provided several examples of how to read and filter partitioned parquet files. You can read a subset of columns in the file. It reads as a spark dataframe april_data = sc.read.parquet ('somepath/data.parquet… See the user guide for more details.
Web Pandas.read_Parquet(Path, Engine='Auto', Columns=None, Storage_Options=None, Use_Nullable_Dtypes=_Nodefault.no_Default, Dtype_Backend=_Nodefault.no_Default, **Kwargs) [Source] #.
Web pandas.read_parquet¶ pandas.read_parquet (path, engine = 'auto', columns = none, ** kwargs) [source] ¶ load a parquet object from the file path, returning a dataframe. Data = pd.read_parquet(data.parquet) # display. You can choose different parquet backends, and have the option of compression. Web 5 i am brand new to pandas and the parquet file type.
Using Pandas’ Read_Parquet() Function And Using Pyarrow’s Parquetdataset Class.
Web df = pd.read_parquet('path/to/parquet/file', columns=['col1', 'col2']) if you want to read only a subset of the rows in the parquet file, you can use the skiprows and nrows parameters. Web in this test, duckdb, polars, and pandas (using chunks) were able to convert csv files to parquet. Web reading the file with an alternative utility, such as the pyarrow.parquet.parquetdataset, and then convert that to pandas (i did not test this code). It's an embedded rdbms similar to sqlite but with olap in mind.