Pd Read Parquet
Pd Read Parquet - Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #. This will work from pyspark shell: You need to create an instance of sqlcontext first. Import pandas as pd pd.read_parquet('example_fp.parquet', engine='fastparquet') the above link explains: Is there a way to read parquet files from dir1_2 and dir2_1. Web reading parquet to pandas filenotfounderror ask question asked 1 year, 2 months ago modified 1 year, 2 months ago viewed 2k times 2 i have code as below and it runs fine. This function writes the dataframe as a parquet. From pyspark.sql import sqlcontext sqlcontext = sqlcontext (sc) sqlcontext.read.parquet (my_file.parquet… It reads as a spark dataframe april_data = sc.read.parquet ('somepath/data.parquet… Connect and share knowledge within a single location that is structured and easy to search.
Any) → pyspark.pandas.frame.dataframe [source] ¶. You need to create an instance of sqlcontext first. I get a really strange error that asks for a schema: Web pandas 0.21 introduces new functions for parquet: Web the us department of justice is investigating whether the kansas city police department in missouri engaged in a pattern of racial discrimination against black officers, according to a letter sent. Write a dataframe to the binary parquet format. This function writes the dataframe as a parquet. Web reading parquet to pandas filenotfounderror ask question asked 1 year, 2 months ago modified 1 year, 2 months ago viewed 2k times 2 i have code as below and it runs fine. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, **kwargs) [source] #. Web the data is available as parquet files.
Write a dataframe to the binary parquet format. These engines are very similar and should read/write nearly identical parquet. Web the us department of justice is investigating whether the kansas city police department in missouri engaged in a pattern of racial discrimination against black officers, according to a letter sent. I get a really strange error that asks for a schema: Import pandas as pd pd.read_parquet('example_fp.parquet', engine='fastparquet') the above link explains: Df = spark.read.format(parquet).load('parquet</strong> file>') or. Any) → pyspark.pandas.frame.dataframe [source] ¶. Is there a way to read parquet files from dir1_2 and dir2_1. Any) → pyspark.pandas.frame.dataframe [source] ¶. Import pandas as pd pd.read_parquet('example_pa.parquet', engine='pyarrow') or.

Spark Scala 3. Read Parquet files in spark using scala YouTube
Web dataframe.to_parquet(path=none, engine='auto', compression='snappy', index=none, partition_cols=none, storage_options=none, **kwargs) [source] #. Web the data is available as parquet files. Import pandas as pd pd.read_parquet('example_pa.parquet', engine='pyarrow') or. Web reading parquet to pandas filenotfounderror ask question asked 1 year, 2 months ago modified 1 year, 2 months ago viewed 2k times 2 i have code as below and it runs fine. Parquet_file =.

Parquet from plank to 3strip from MEISTER
Web reading parquet to pandas filenotfounderror ask question asked 1 year, 2 months ago modified 1 year, 2 months ago viewed 2k times 2 i have code as below and it runs fine. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #. Web dataframe.to_parquet(path=none, engine='auto', compression='snappy', index=none, partition_cols=none, storage_options=none, **kwargs) [source] #. Any) → pyspark.pandas.frame.dataframe [source] ¶..

How to read parquet files directly from azure datalake without spark?
Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, **kwargs) [source] #. This function writes the dataframe as a parquet. Is there a way to read parquet files from dir1_2 and dir2_1. I get a really strange error that asks for a schema: Right now i'm reading each dir and merging dataframes using unionall.

python Pandas read_parquet partially parses binary column Stack
Df = spark.read.format(parquet).load('parquet</strong> file>') or. Connect and share knowledge within a single location that is structured and easy to search. Parquet_file = r'f:\python scripts\my_file.parquet' file= pd.read_parquet (path = parquet… Web sqlcontext.read.parquet (dir1) reads parquet files from dir1_1 and dir1_2. Any) → pyspark.pandas.frame.dataframe [source] ¶.

Modin ray shows error on pd.read_parquet · Issue 3333 · modinproject
Web pandas 0.21 introduces new functions for parquet: Web to read parquet format file in azure databricks notebook, you should directly use the class pyspark.sql.dataframereader to do that to load data as a pyspark dataframe, not use pandas. Df = spark.read.format(parquet).load('parquet</strong> file>') or. Right now i'm reading each dir and merging dataframes using unionall. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default,.

How to resolve Parquet File issue
Web the us department of justice is investigating whether the kansas city police department in missouri engaged in a pattern of racial discrimination against black officers, according to a letter sent. Df = spark.read.format(parquet).load('parquet</strong> file>') or. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, **kwargs) [source] #. Is there a way to read parquet files from dir1_2 and dir2_1. Web dataframe.to_parquet(path=none,.

pd.read_parquet Read Parquet Files in Pandas • datagy
Connect and share knowledge within a single location that is structured and easy to search. I get a really strange error that asks for a schema: From pyspark.sql import sqlcontext sqlcontext = sqlcontext (sc) sqlcontext.read.parquet (my_file.parquet… These engines are very similar and should read/write nearly identical parquet. You need to create an instance of sqlcontext first.

Parquet Flooring How To Install Parquet Floors In Your Home
Df = spark.read.format(parquet).load('parquet</strong> file>') or. Connect and share knowledge within a single location that is structured and easy to search. From pyspark.sql import sqlcontext sqlcontext = sqlcontext (sc) sqlcontext.read.parquet (my_file.parquet… Is there a way to read parquet files from dir1_2 and dir2_1. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, **kwargs) [source] #.
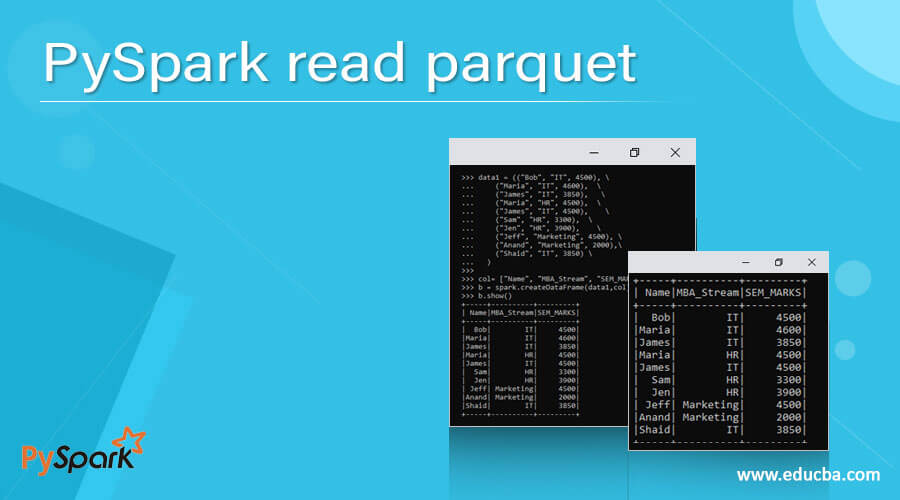
PySpark read parquet Learn the use of READ PARQUET in PySpark
Web 1 i'm working on an app that is writing parquet files. Web dataframe.to_parquet(path=none, engine='auto', compression='snappy', index=none, partition_cols=none, storage_options=none, **kwargs) [source] #. Any) → pyspark.pandas.frame.dataframe [source] ¶. Web 1 i've just updated all my conda environments (pandas 1.4.1) and i'm facing a problem with pandas read_parquet function. Is there a way to read parquet files from dir1_2 and dir2_1.
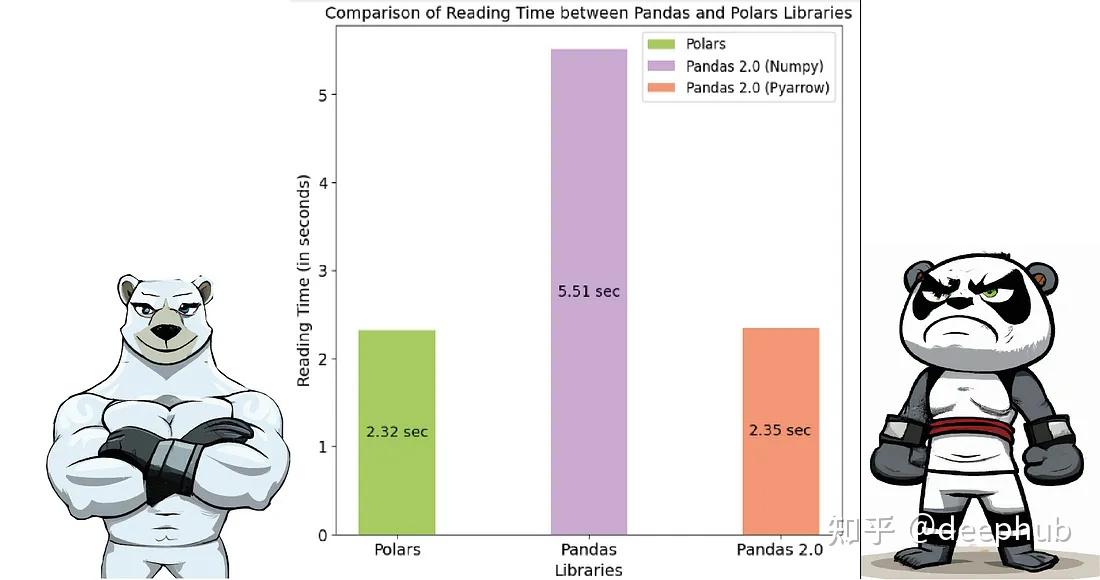
Pandas 2.0 vs Polars速度的全面对比 知乎
Write a dataframe to the binary parquet format. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #. Parquet_file = r'f:\python scripts\my_file.parquet' file= pd.read_parquet (path = parquet… I get a really strange error that asks for a schema: Web pandas 0.21 introduces new functions for parquet:
You Need To Create An Instance Of Sqlcontext First.
Web sqlcontext.read.parquet (dir1) reads parquet files from dir1_1 and dir1_2. Parquet_file = r'f:\python scripts\my_file.parquet' file= pd.read_parquet (path = parquet… Write a dataframe to the binary parquet format. Web the us department of justice is investigating whether the kansas city police department in missouri engaged in a pattern of racial discrimination against black officers, according to a letter sent.
Df = Spark.read.format(Parquet).Load('Parquet</Strong> File>') Or.
I get a really strange error that asks for a schema: From pyspark.sql import sqlcontext sqlcontext = sqlcontext (sc) sqlcontext.read.parquet (my_file.parquet… Web to read parquet format file in azure databricks notebook, you should directly use the class pyspark.sql.dataframereader to do that to load data as a pyspark dataframe, not use pandas. Web the data is available as parquet files.
This Function Writes The Dataframe As A Parquet.
Is there a way to read parquet files from dir1_2 and dir2_1. These engines are very similar and should read/write nearly identical parquet. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, **kwargs) [source] #. It reads as a spark dataframe april_data = sc.read.parquet ('somepath/data.parquet…
Web 1 I'm Working On An App That Is Writing Parquet Files.
Right now i'm reading each dir and merging dataframes using unionall. Web pandas 0.21 introduces new functions for parquet: Import pandas as pd pd.read_parquet('example_pa.parquet', engine='pyarrow') or. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #.